Hello World: Your First Agent
With the minerl package installed on your system you can
now make your first agent in Minecraft!
To get started, let’s first import the necessary packages
import gym
import minerl
Creating an environment
Now we can choose any one of the many environments included
in the minerl package. To learn more about the environments
checkout the environment documentation.
For this tutorial we’ll choose the MineRLNavigateDense-v0
environment. In this task, the agent is challenged with using
a first-person perspective of a random Minecraft map and
navigating to a target.
To create the environment, simply invoke gym.make
env = gym.make('MineRLNavigateDense-v0')
Caution
Currently minerl only supports environment rendering in headed environments
(servers with monitors attached).
In order to run minerl environments without a head use a software renderer
such as xvfb:
xvfb-run python3 <your_script.py>
Alternatively, you can use an environment variable which automatically adds xvfb when launching MineRL:
MINERL_HEADLESS=1 python3 <your_script.py>
Note
If you’re worried and want to make sure something is happening behind the scenes install a logger before you create the envrionment.
import logging
logging.basicConfig(level=logging.DEBUG)
env = gym.make('MineRLNavigateDense-v0')
Taking actions
As a warm up let’s create a random agent. 🧠
Now we can reset this environment to its first position and get our first observation from the agent by resetting the environment.
Note
The first time you run this command to complete, it will take a while as it is recompiling Minecraft with the MineRL simulator mod (can be as long as 15-30 minutes)!
obs = env.reset()
The obs variable will be a dictionary containing the following
observations returned by the environment. In the case of the
MineRLNavigate-v0 environment, three observations are returned:
pov, an RGB image of the agent’s first person perspective;
compassAngle, a float giving the angle of the agent to its
(approximate) target; and inventory, a dictionary containing
the amount of 'dirt' blocks in the agent’s inventory (this
is useful for climbing steep inclines).
{
'pov': array([[[ 63, 63, 68],
[ 63, 63, 68],
[ 63, 63, 68],
...,
[ 92, 92, 100],
[ 92, 92, 100],
[ 92, 92, 100]],,
...,
[[ 95, 118, 176],
[ 95, 119, 177],
[ 96, 119, 178],
...,
[ 93, 116, 172],
[ 93, 115, 171],
[ 92, 115, 170]]], dtype=uint8),
'compass': {'angle': array(-63.48639)},
'inventory': {'dirt': 0}
}
Note
To see the exact format of observations returned from
and the exact action format expected by env.step
for any environment refer to the environment reference documentation!
Now let’s take actions through the environment until time runs out
or the agent dies. To do this, we will use the normal OpenAI Gym env.step
method.
done = False
while not done:
action = env.action_space.sample()
obs, reward, done, _ = env.step(action)
After running this code the agent should move sporadically until done flag is set to true.
If you see a Minecraft window, it does not update while agent is playing, which is intended behaviour.
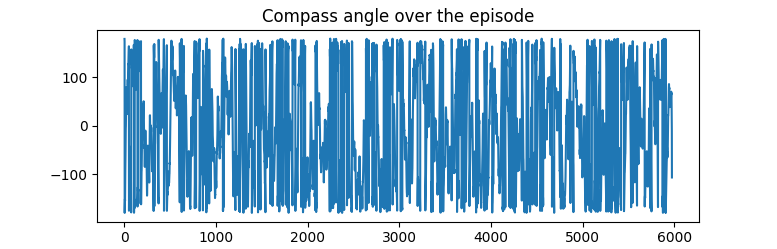
To confirm that our agent is at least qualitatively
acting randomly, on the right is a plot of the compass angle over the course of the experiment.
No-op actions and a better policy
Now let’s make a hard-coded agent that actually runs towards the target. 🧠🧠🧠
To do this at every step of the environment we will take the noop
action with a few modifications; in particular, we will only move forward,
jump, attack, and change the agent’s direction to minimize
the angle between the agent’s movement direction and it’s target, compassAngle.
import minerl
import gym
env = gym.make('MineRLNavigateDense-v0')
obs = env.reset()
done = False
net_reward = 0
while not done:
action = env.action_space.noop()
action['camera'] = [0, 0.03*obs["compass"]["angle"]]
action['back'] = 0
action['forward'] = 1
action['jump'] = 1
action['attack'] = 1
obs, reward, done, info = env.step(
action)
net_reward += reward
print("Total reward: ", net_reward)
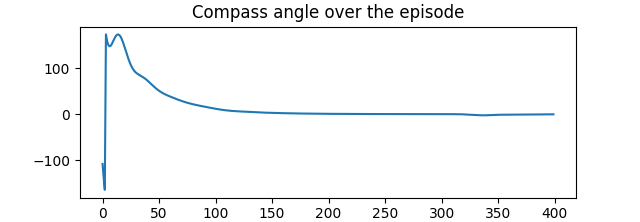
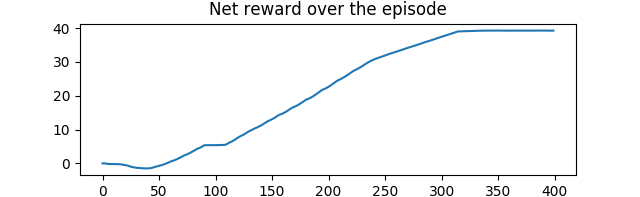
After running this agent, you should notice marekedly less sporadic
behaviour. Plotting both the compassAngle and the
net reward over the episode confirm that this policy performs
better than our random policy.
Congratulations! You’ve just made your first agent using the
minerl framework!